MLSys_分布式开发(选读)
序列并行
Megatron
Reducing Activation Recomputation in Large Transformer Models
https://arxiv.org/pdf/2205.05198
Abstract
在大模型训练过程中显存占用过大往往成为瓶颈,一般会通过重计算的方式降低显存占用,但会带来额外的计算代价。本文提出sequece parallel(序列并行,简称SP)和selective activation recomputation两种方法,可以结合TP有效减少不必要的计算量。
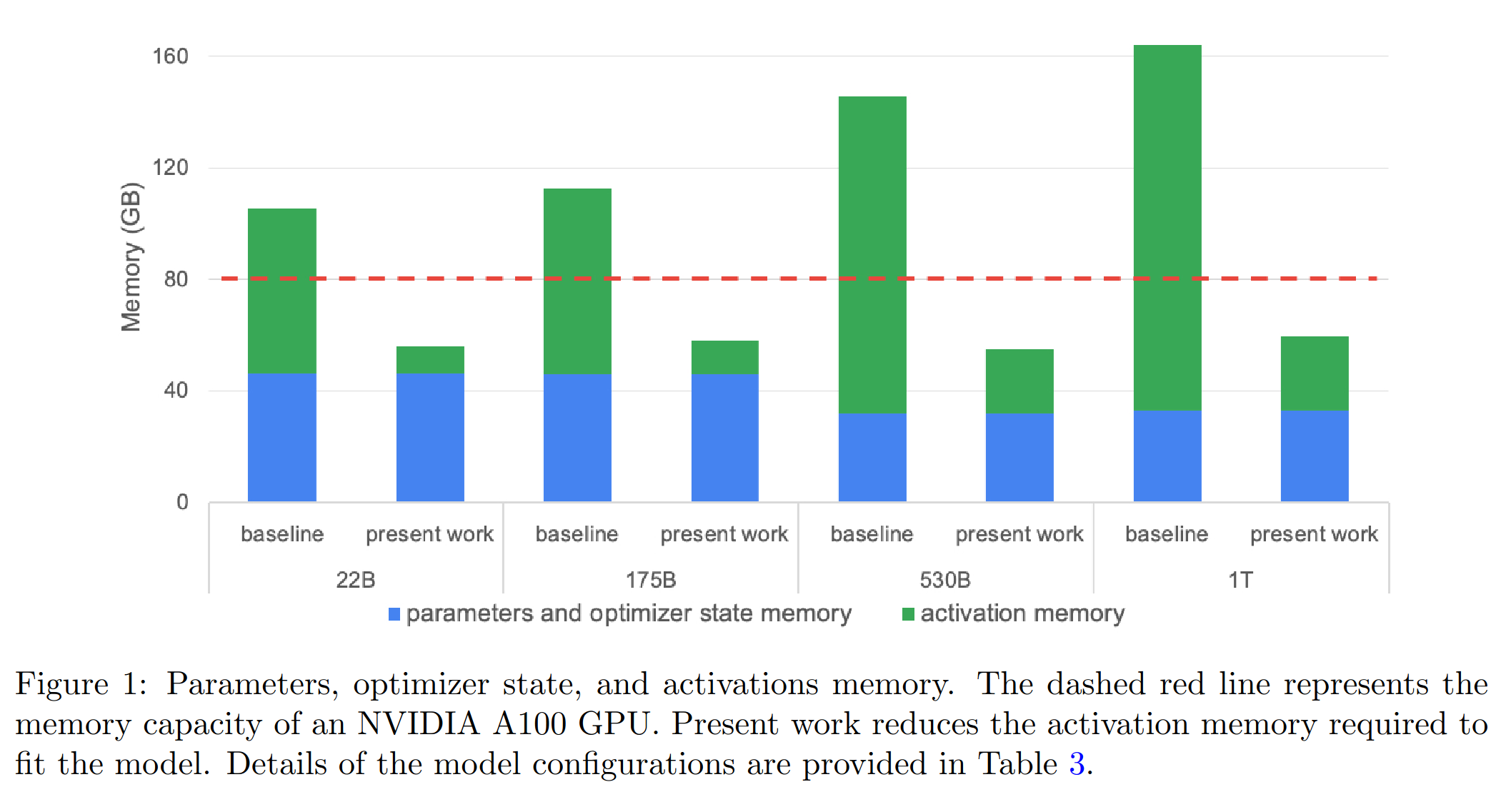
下图中绿色部分表示不同参数级别模型中需要用于保存activation需要的显存大小,蓝色部分表示不同参数级别模型中需要用于保存parameter和optimizer state需要的显存大小。红色线表示baseline(A100的显存)80G。
通过对比可以发现,原本单A100跑不了的模型,经过SP优化后可以在单A100上运行了,这就给我们加大数据量和多机并行提供了极大的便利
Activation Memory
本文以Transformer结构为例估算Activation Memory,Activation指FWD和BWD梯度计算中创建的所有tensor。不包含模型参数大小和优化器中状态大小,但是包含dropout用到的mask tensor。
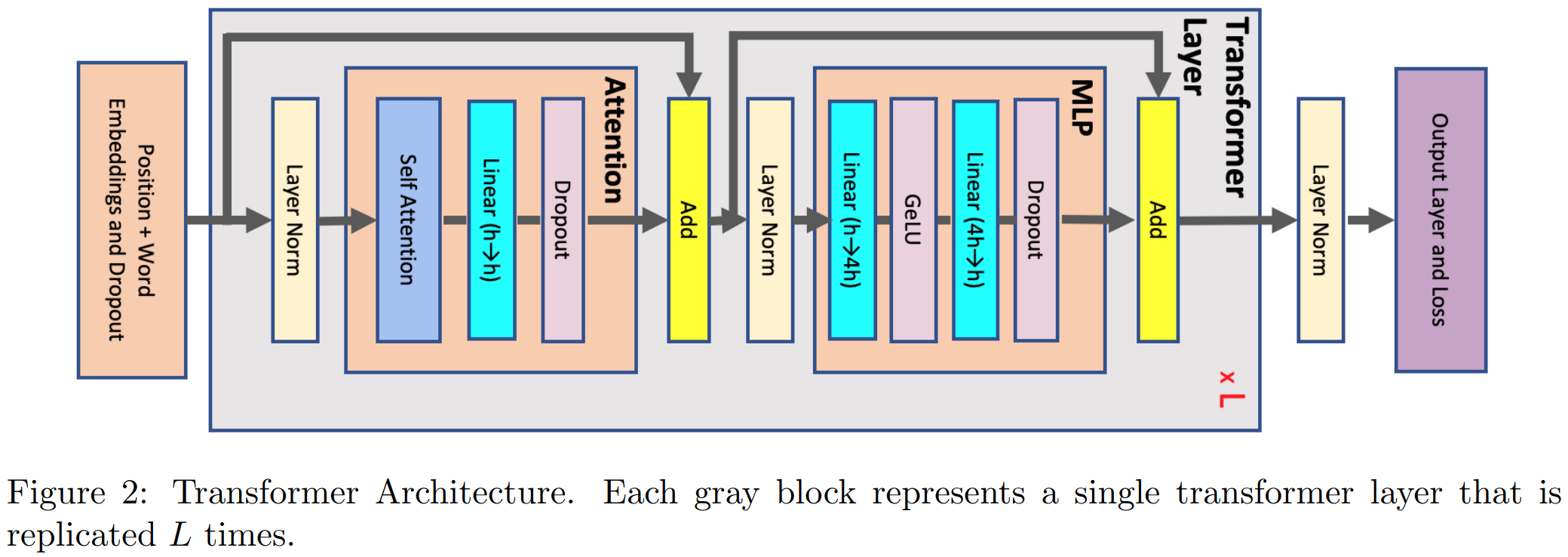
本文推导与假设中用到了以下几个参量:
本文假设h极大(实际上一般也确实极大), 认为2sb远小于sbh, 即只考虑中间过程的Memory(shb), 忽略输入输出的Memory
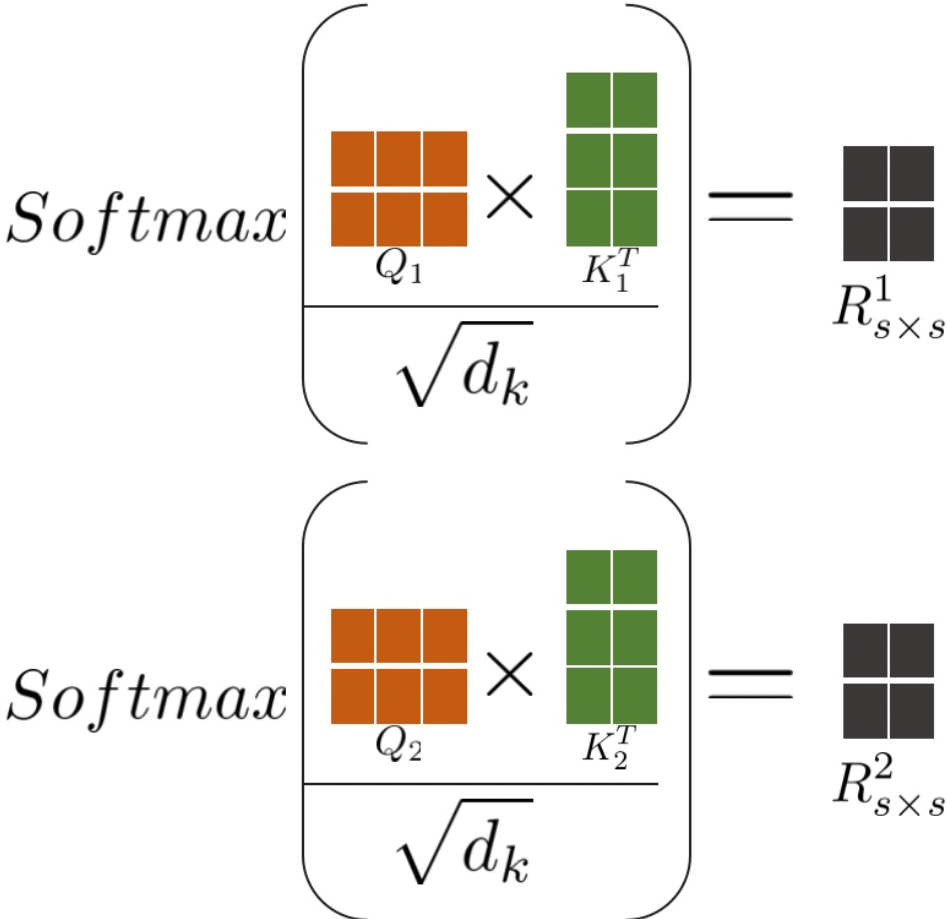
对于Attention模块,这一部分依赖于softmax实现:
具体实现图例见下:
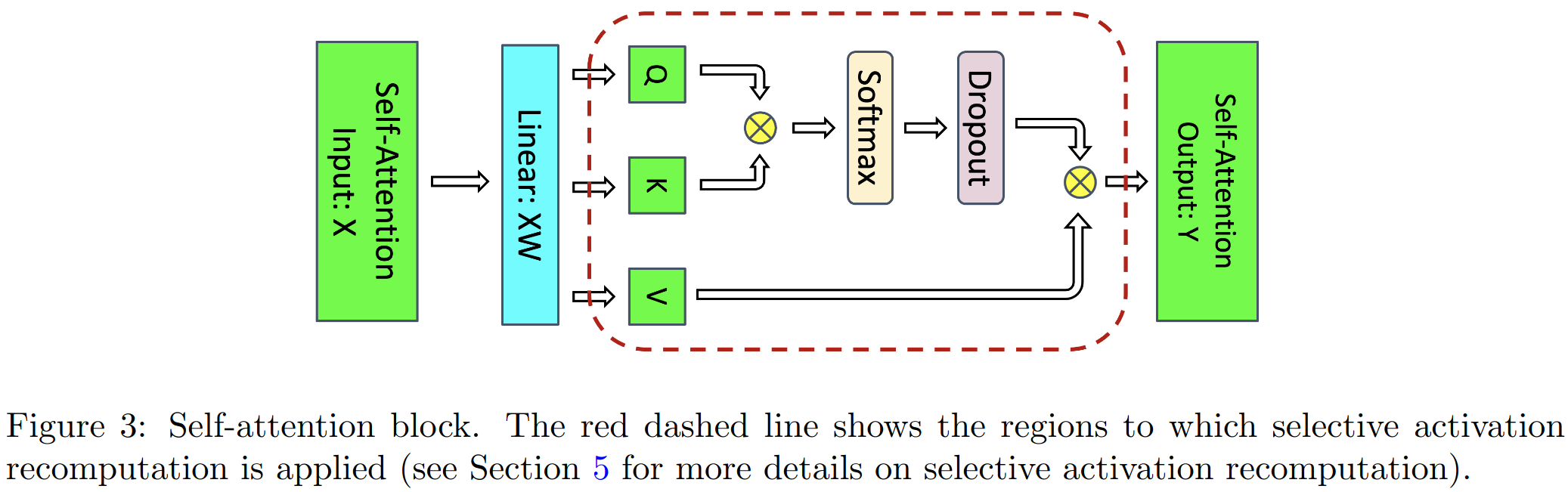
对于Attention块来说,输入的元素个数为sbh个,每个元素以半精度(2 bytes)来进行存储的话,对应输入的元素大小为2sbh bytes
Attention块中包含一个self-attention、一个linear(线性映射层)和attention dropout层。对于linear需要保存输入的Activation大小为2sbh, 对于attention dropout层需要mask的大小为sbh(对于一个元素的mask只用1个bytes),对于self-attention块的Activation Memory的计算有以下几块:
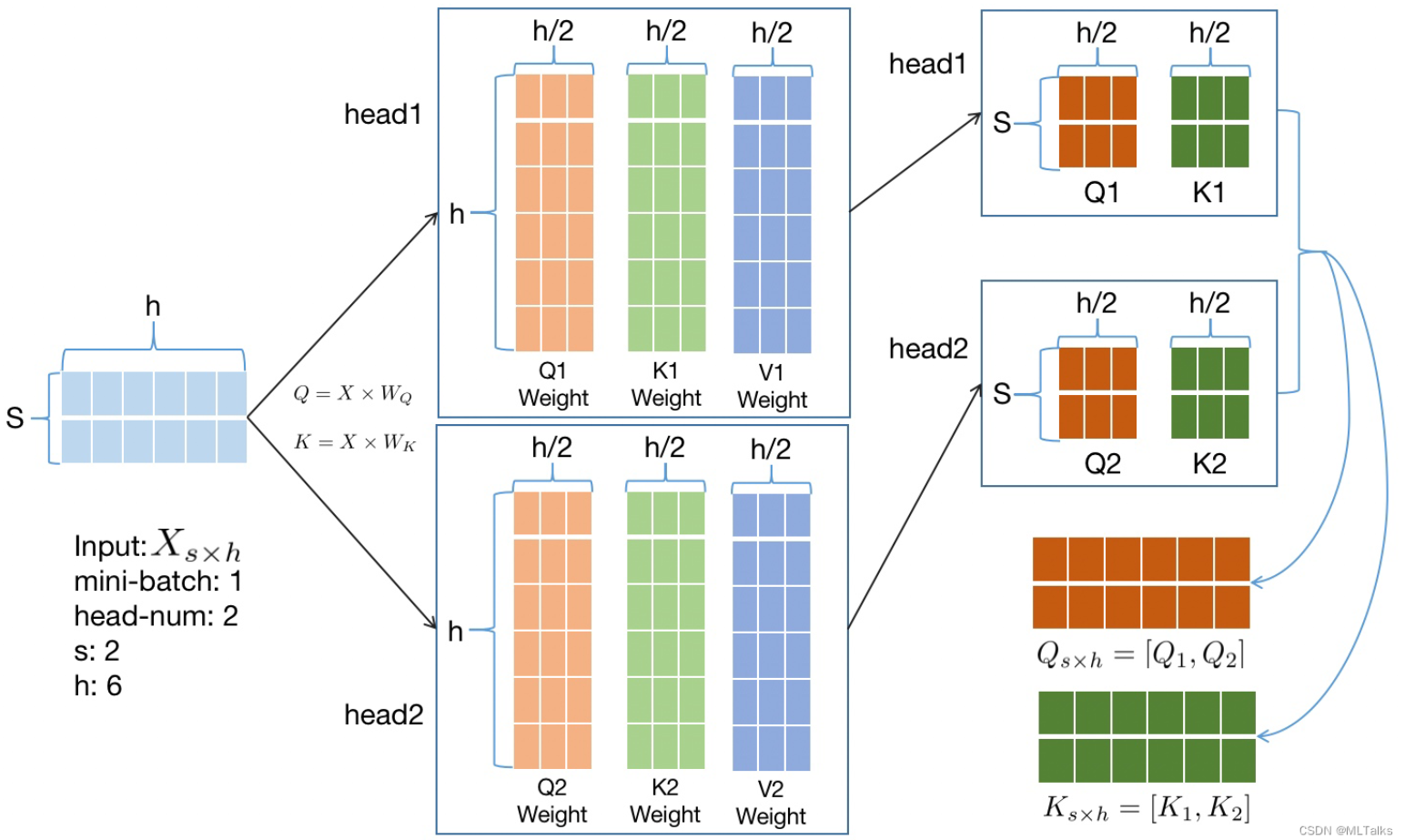
- Query(Q),Key(K),Value(V)
matrix mul:input共享,元素个数为sbh个,总大小是2sbh bytes。 - 矩阵相乘:需要分别创建保存和的矩阵,每个矩阵元素总大小为
2sbh bytes, 总共大小为4sbh bytes
原始Self-Attention例子(此处X切分仅作示意,实际上是按行切分的):
dropout的mask层矩阵的大小与softmax的输出一样,元素个数都是个,但mask单个元素的大小只用
1 bytes即可,总的大小为 bytessoftmax的输出也会用于反向的计算,需要缓存下来,对应大小 bytes
矩阵的大小之前没有统计,和、矩阵一样,大小也是
2sbh bytes
Attention 模块总的大小为 11sbh + 5 bytes。
MLP的Activation大小计算:MLP中有两层线性layer,分别存储输入矩阵大小为2sbh bytes和8sbh bytes;GeLU的反向也需要对输入进行缓存,大小为8sbh bytes; dropout层需要sbh bytes; 总大小为19sbh。
LayerNorm的Activation大小计算:每个LayerNorm层的输入需要2sbh大小,有两个LayerNorm层,总大小为4sbh bytes.
一层transformer的memory总的大小为:
Tensor Parallel
在TP并行中只在Attention和MLP两个地方进行了并行计算,对于两块的输入并没有并行操作。
图中和互为共轭(conjugate),在前向时不做操作,反向时执行all-reduce;在前向时执行all-reduce, 反向时不做操作。
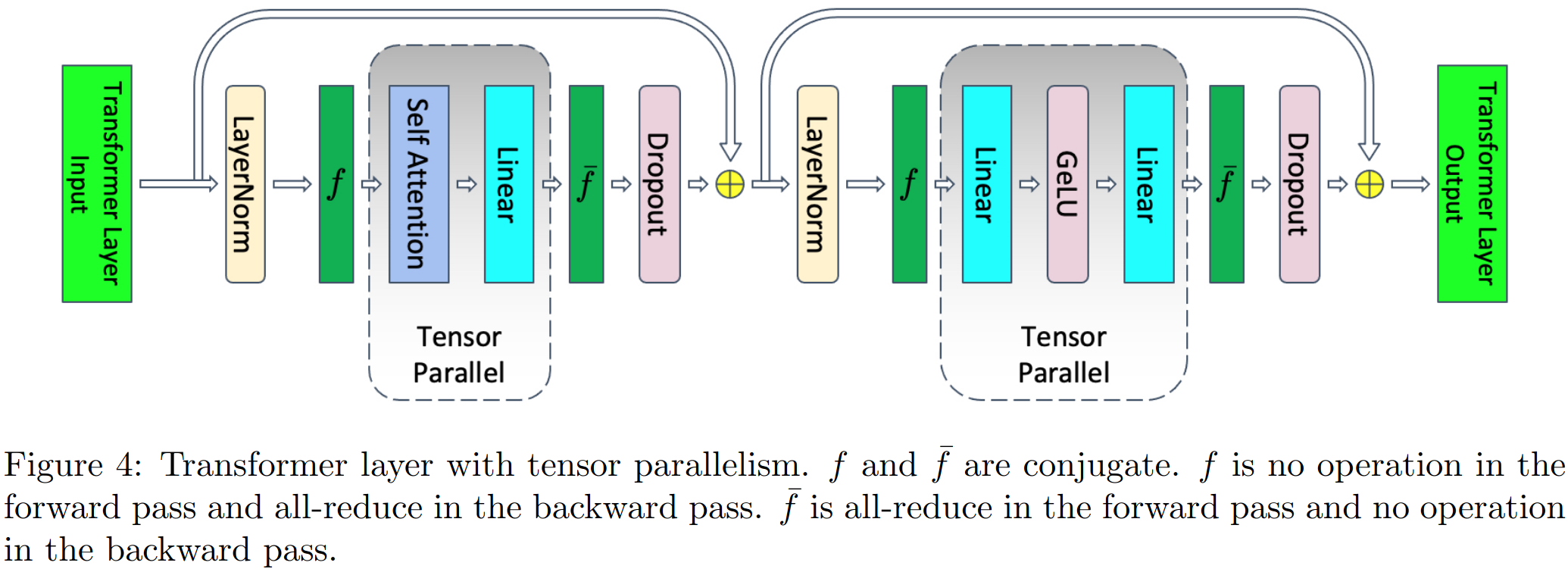
考虑TP并行(并行度为),并行部分有MLP的Linear部分(18sbh bytes)和Attention的QKV部分(6sbh bytes), ActivationMemoryPerLayer的值降为:
Sequence Parallel
在Tensor模型并行基础上提出了Sequence Parallel,对于非TP并行的部分在sequence维度都是相互独立的,所以可以在sequence维度上进行拆分(即sequence parallel)。
拆分后如下图,和替换为和在前向是reduce-scatter, 反向是all-gather通信。
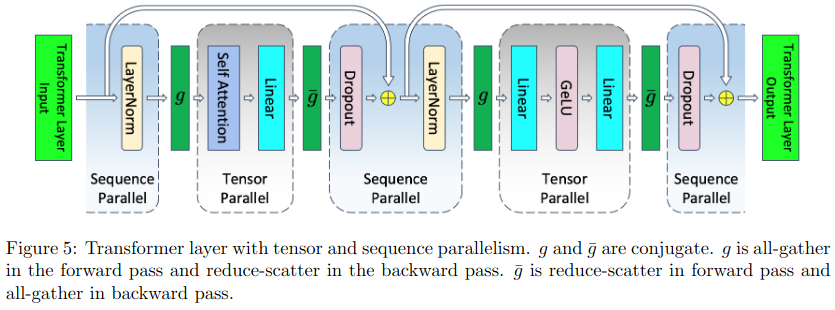
以MLP为例,详细说明拆分步骤:
MLP层由两个Linear层组成,对应的计算公式如下, 其中的大小为;和是Linear的权重weight矩阵,大小为和
论文做如下符号说明:
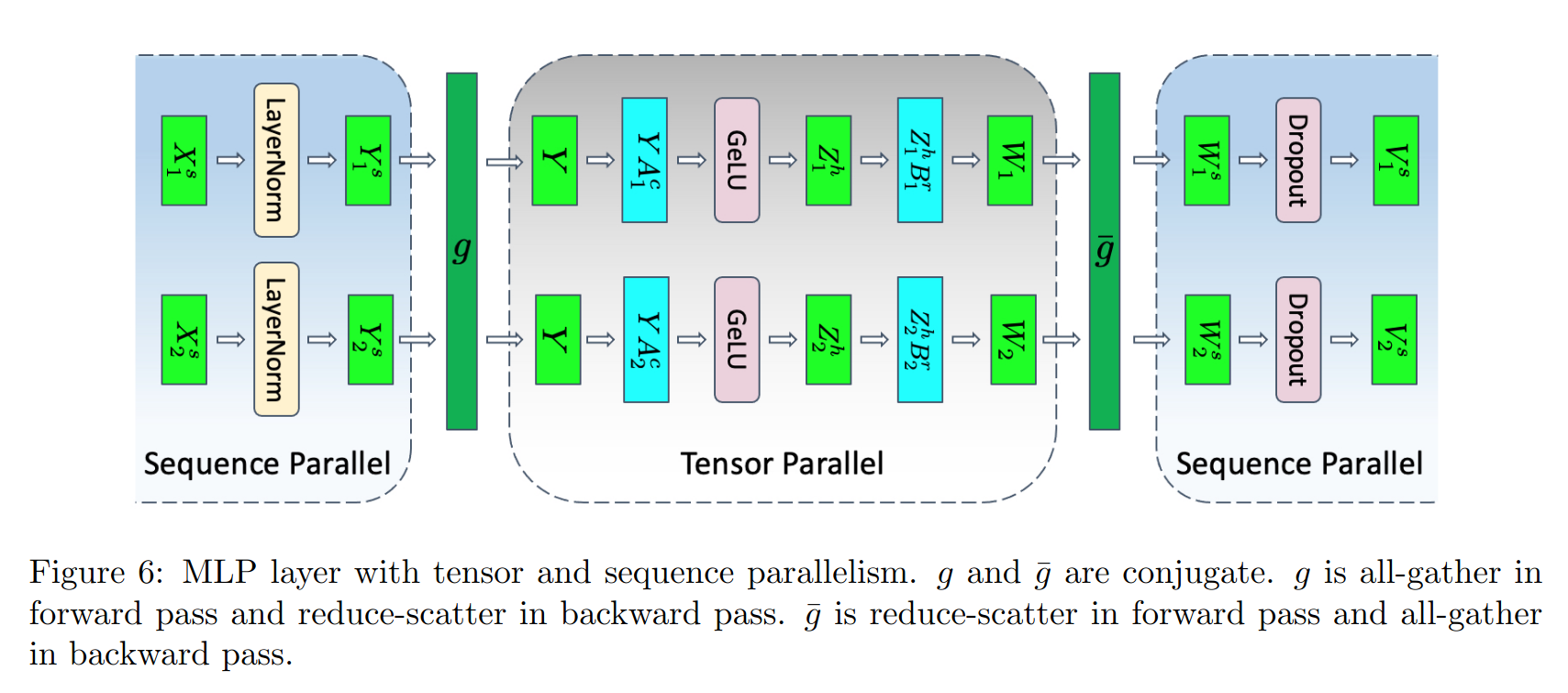
- 对按sequence维度切分, ,LayerNorm的结果;
- 考虑GeLU非线性,进行all-gather,计算;
- 对进行列切分的tensor并行,得到结果和
- 对进行行切分的tensor并行,得到结果和
- 得到和后进行reduce-scatter
具体过程见下:
TP在一次前向和后向总共有4次的all-reduce操作,在SP一次前向和后向总共有4次all-gather和4次reduce-scatter操作。ring all-reduce 执行过程中有两步,先是一个reduce-scatter然后一个all-gather,SP没有引入更多的通信代价。
DeepSpeed-Ulysses
DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Modelshttps://arxiv.org/pdf/2309.14509
DeepSpeed在知乎也有官号, 这里仅作简述, 官号本身讲的也非常不错, 链接在这儿:https://zhuanlan.zhihu.com/p/652206513
简介
- 长序列在LLM应用中非常重要, 长上下文的保存有助于LLM推理, 需求大token和长Sequence的输入
- 现有的DP TP PP不能解决序列维度的扩展问题
- 现有的序列并行方法依托内存通讯, 不够高效
DeepSpeed-Ulysses将各个样本在序列维度上分割给参与的GPU。在attention计算之前,它对已分割的查询(Q)、键(K)和值(V)执行all-to-all通信操作,以使每个GPU接收完整的序列,但仅用于注意力头的非重叠子集。
这使得参与的GPU可以并行计算不同的注意力头。最后,DeepSpeed-Ulysses还使用另一个all-to-all来在注意力头上收集结果,同时重新在序列维度上进行分区。
DeepSpeed-Ulysses的核心设计
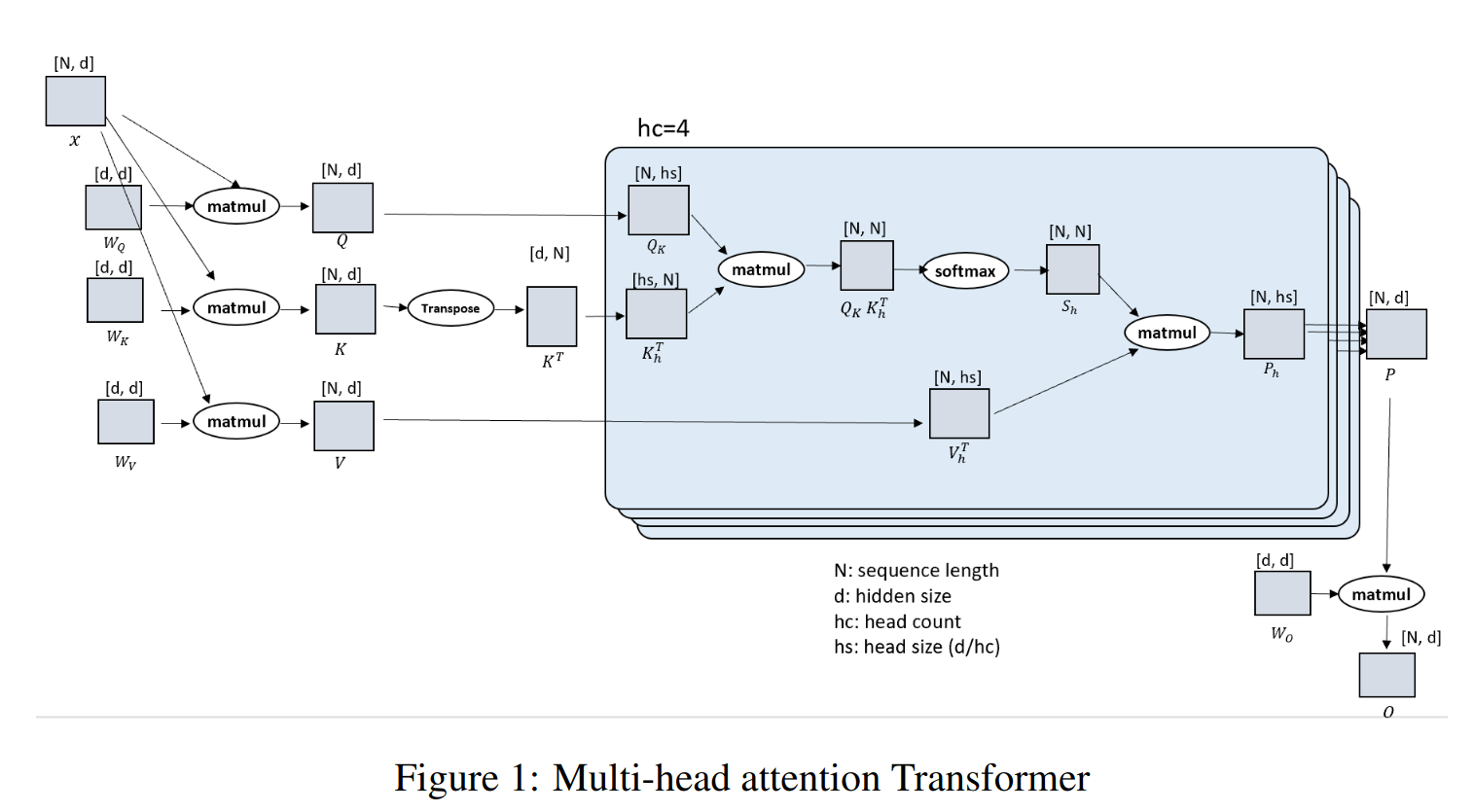
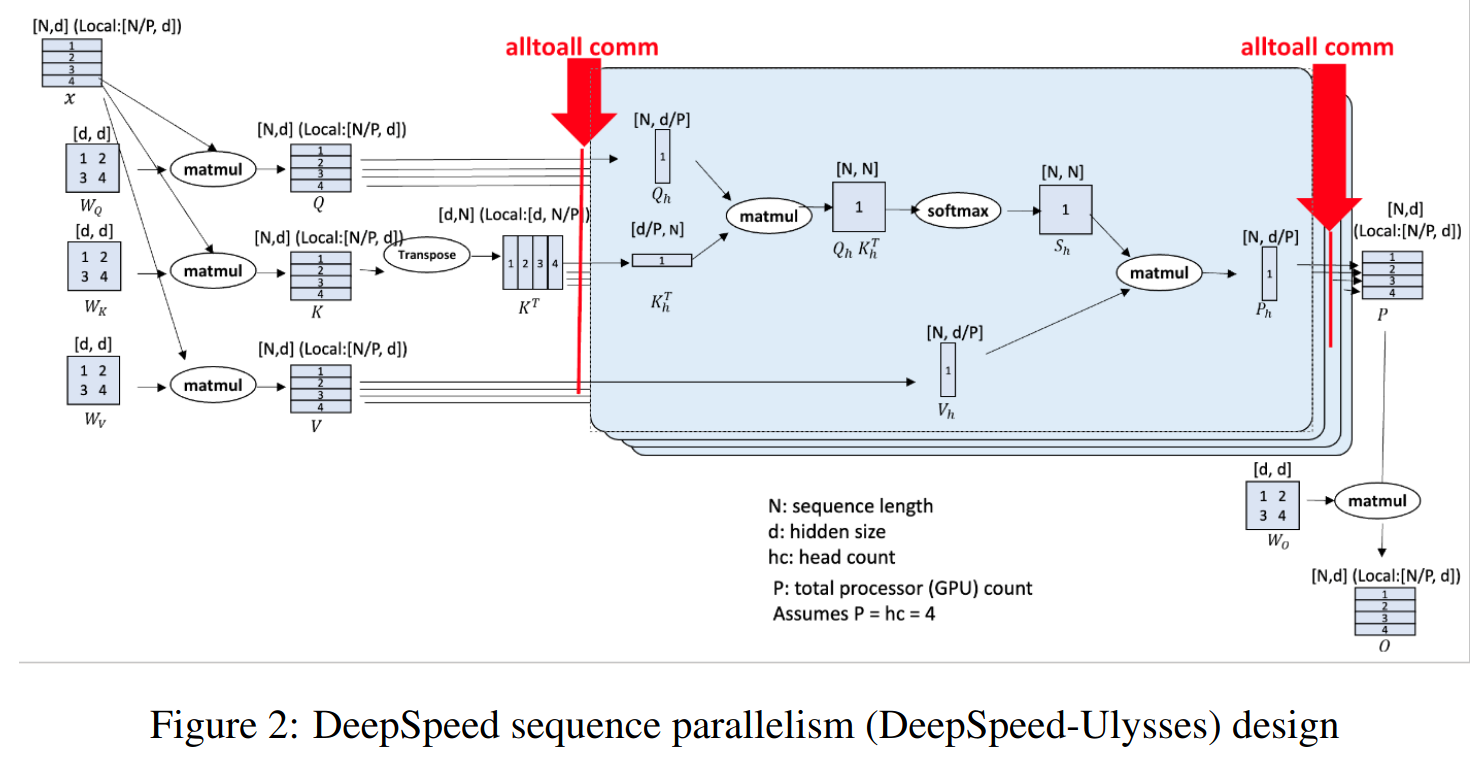
与已知的Transformer架构一样,设计由N个输入序列在P个可用设备上分区组成。每个本地N/P分区都被投影到查询(Q)、键(K)和值(V)嵌入中。接下来,(QKV) 嵌入通过参与计算设备之间的高度优化的全对全集合(all-to-all collectives)进行全局的 QKV 收集。在全对全集合后,每个头的注意力计算形式为:
注意力计算后,另一个全对全集合将注意力计算的输出上下文张量转换为序列(N/P)并行,用于Transformer模型层的剩余模块中的后续操作。
Sequence Parallelism
Sequence Parallelism: Long Sequence Training from System Perspectivehttps://arxiv.org/pdf/2105.13120
论文背景
和Ulysses一样, 这个SP也是目的也是解决输入序列规模问题, 而不是像Megtron-LM一样解决计算过程中的内存占用问题.
文章将自己的SP流程和PP TP模型做了比较: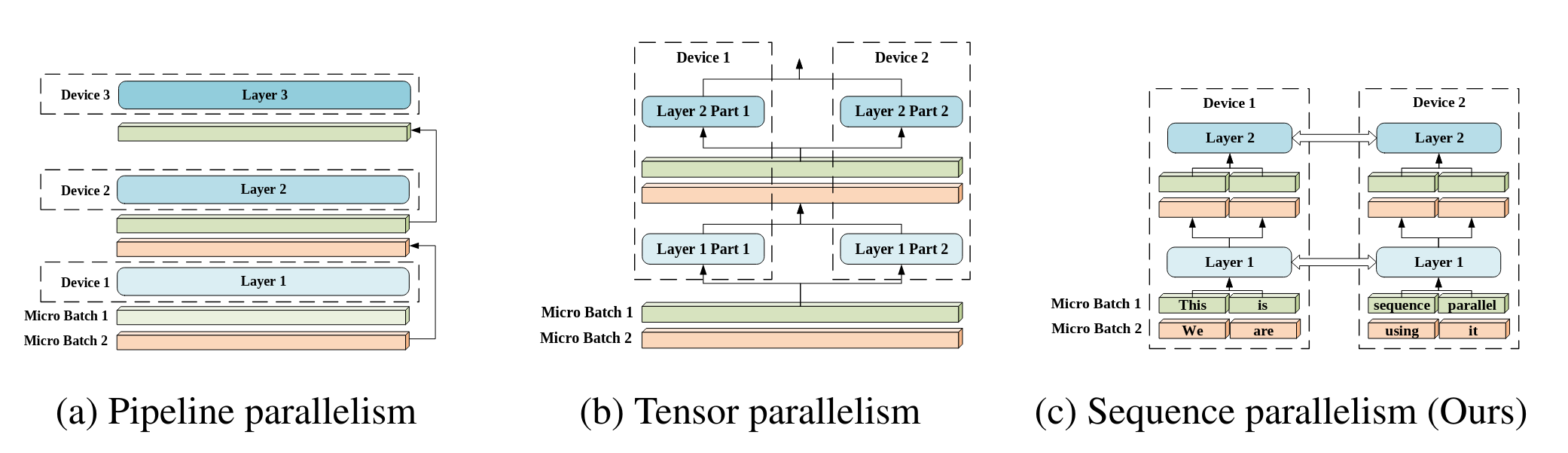
主要工作
本文认为SP最主要的问题是跨设备如何计算sub-sequences的attention scores问题,为了解决该问题,本文设计出Ring Self-Attention来解决此问题.
感觉想法来源于Ring-AllReduce, 而且只优化了自注意力部分
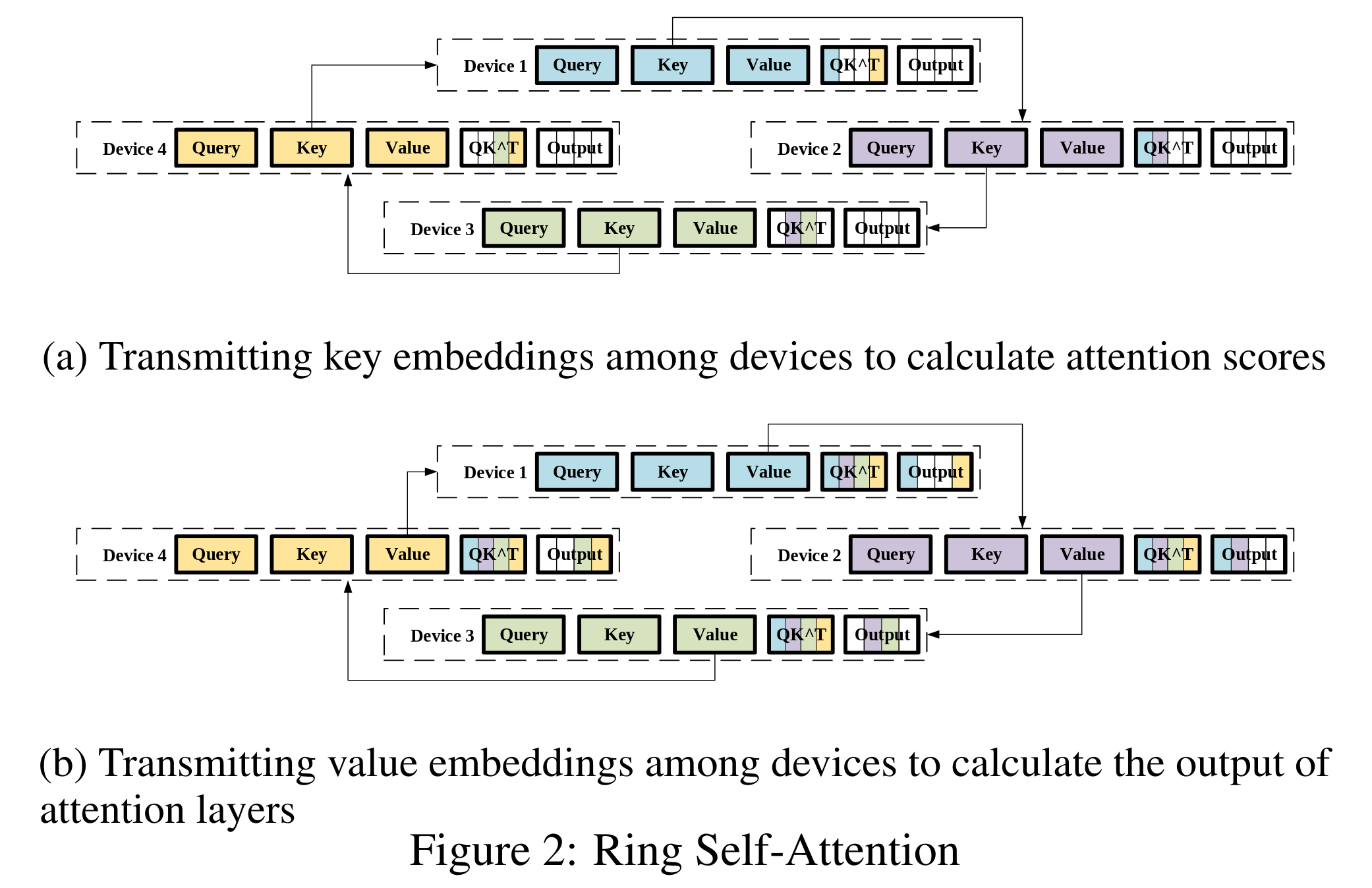
RSA感觉就是将输入序列进行切分, 通过将序列整体切分成小的chunk, 使得每一个chunk都尽可能大, 用commnication换取序列长度
Ring-Attention
Ring Attention with Blockwise Transformers for Near-Infinite Contexthttps://arxiv.org/pdf/2310.01889
背景
老生常谈的transformer长序列要求,不做赘述。
Ring Attention
本文提出以分块方式执行Self-Attention和FWD计算,多机分布序列维度,从而实现并发计算和通信.
由于该方法将环中主机设备之间的Key Value Block通信与compute重叠,因此将其命名:环注意(Ring Attention)
具体实现:
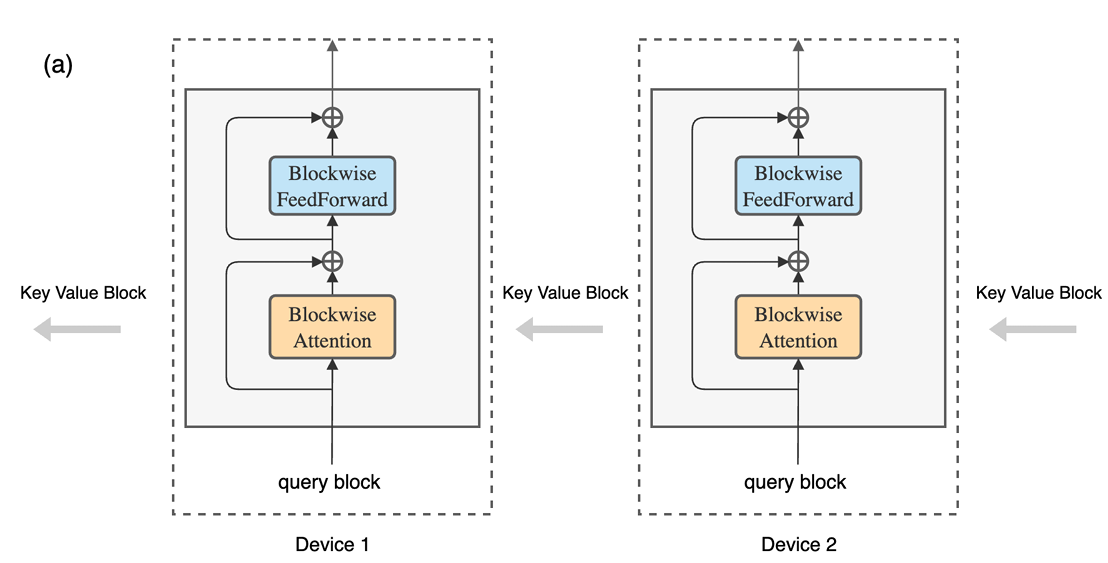
该方法在主机设备之间构建Self-Attention的外循环,每个主机设备具有一个query block,并通过Key Value Block遍历主机Ring,以逐块的方式进行注意力和前馈网络计算。
当计算Self-Attention时,每个主机将Key Value Block发送到下一个主机,同时从前一个主机接收Key Value Block。
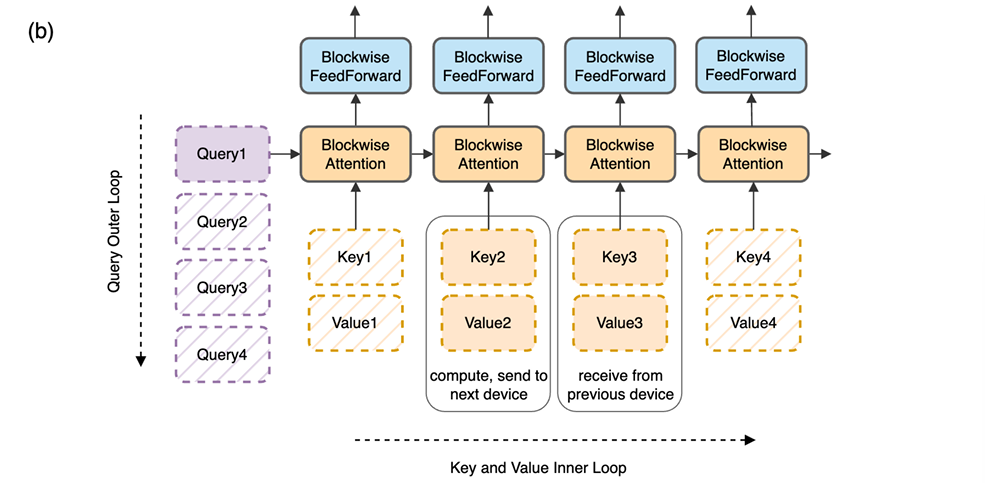
对于内循环,每个设备计算其各自的Self-Attention和FWD。在内循环期间,每个设备将用于compute的Key Value Block的副本发送到Ring中的下一个设备,同时从前一个设备接收Key Value Block。
由于块计算比块传输需要更长的时间,与标准Transformer相比,此过程不会增加开销。
这种Ring Attention方式可以突破序列长度限制(对于单卡内存需求来说,而非模型整体来说),因为我们在Attention之前矩阵乘就已经切分了Squence,让每一个卡分批成环去跑一小批token
这种方式理论上并不影响训练结果,因为最小训练单位还是一个token(对Squence做切分时的原则)
天才般的想法!(我觉得)好吧也需要堆卡出奇迹
那么代价呢? 文章的训练测试规模比较小,能否在大规模训练时取得想象中的线性效果,还是未知数 文章只对Attention和FWD操作做了优化,基础操作还有进一步优化的空间,可以考虑采用4D并行。
DISTFLASHATTN
https://arxiv.org/pdf/2310.03294
背景
部分SP方法,如Ring Attention缺少高效的Attention实现。(前文提及的基础操作还有进一步优化的空间)
论文方法
文章针对三个challenge提出了三个解决方法,解决了高校Attention实现、分布式应用等问题。
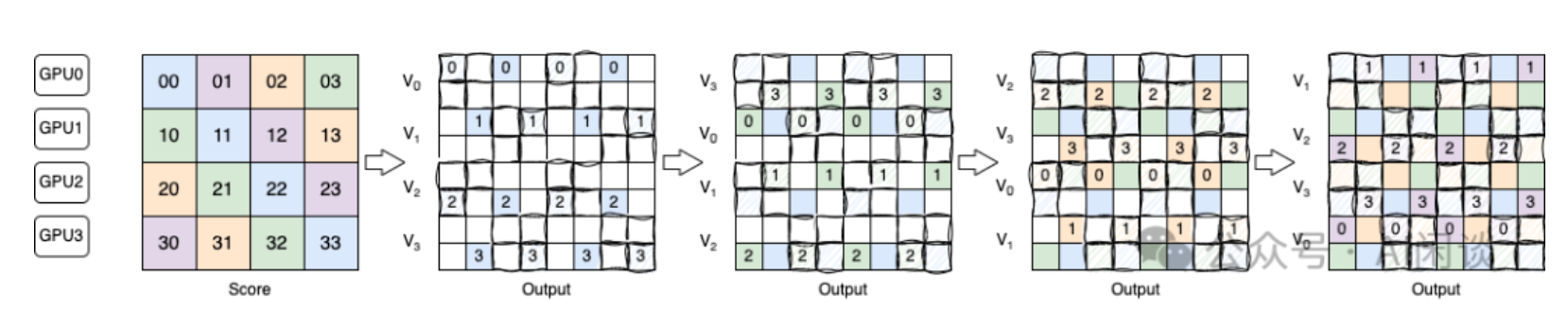
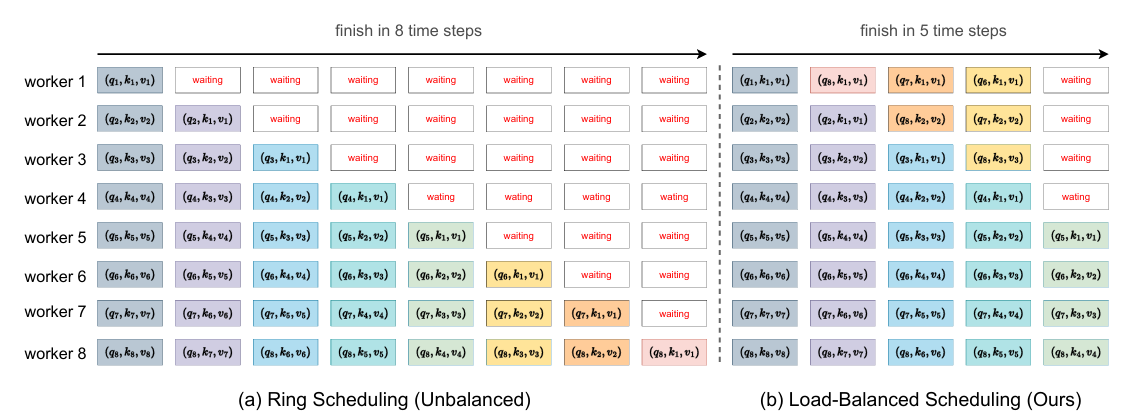
token-level workload imbalance
这主要是由于causal mask引起的attention计算问题,如果简单分块计算约会有1/2的计算资源浪费。
因为一般causal mask就是会用矩阵以对角线为界mask数据, 按照ring拓扑结构进行计算也会有约一半的CPU处于等待状态。
针对这个问题,论文中提出Token-level workload balancing的调度算法,通过给空闲的worker来fetch部分key-value数据,计算后再传递回去。
Prohibitive communication overhead
需要通信汇总不同worker上的attention结果,本文提出通过计算 prefetch张量来完成通信的覆盖,实现依赖于P2P的通信模式。

Loadbalanced scheduling with communication and computation overlap
huggingface中采用的Recomputation的检查点放置不合理,导致相对高的还原计算代价。
下面是两种重计算策略的对比: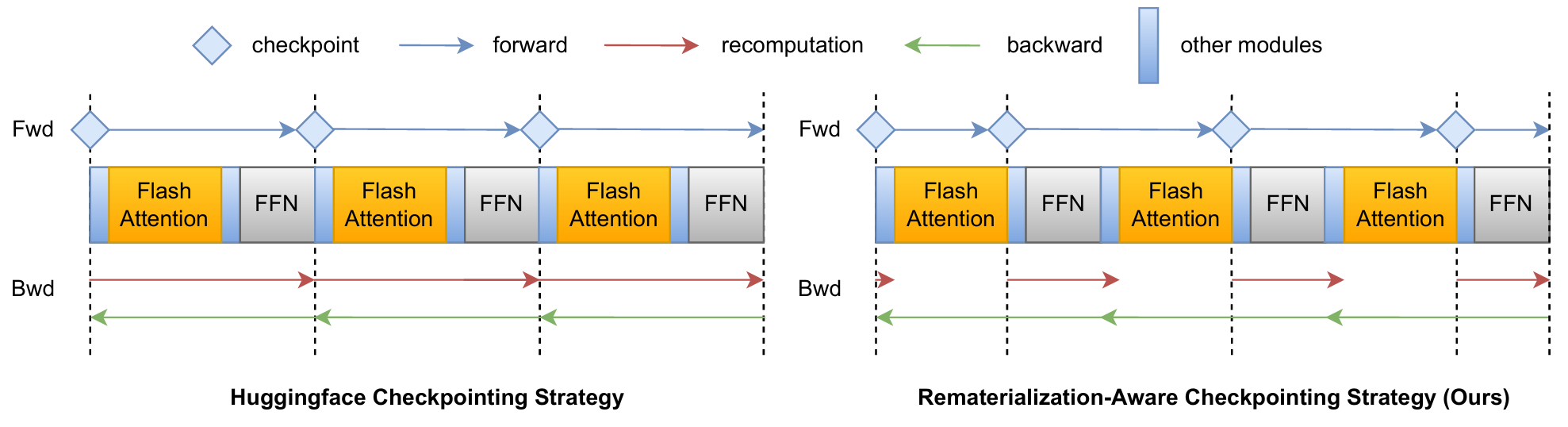
DFA相较HF每一个FlashAttention+FFN约能够减少一个FA的计算量。FlashAttention部分的梯度更新为三个矩阵,可以通过FA的输出结果完成更新,因此保存FA的结果便可计算三者的矩阵。